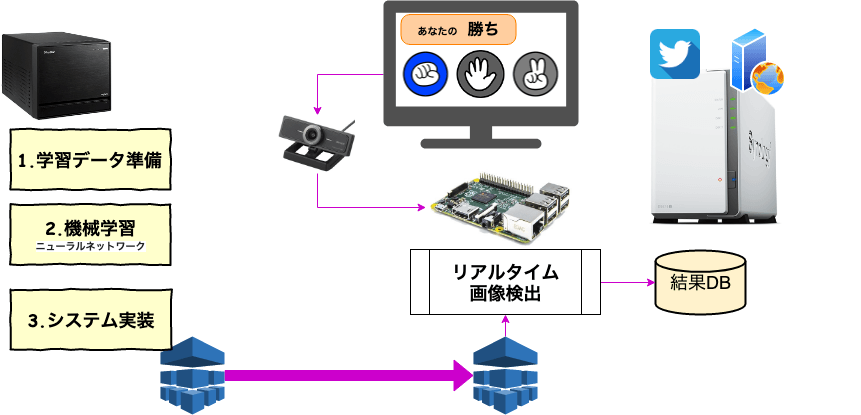
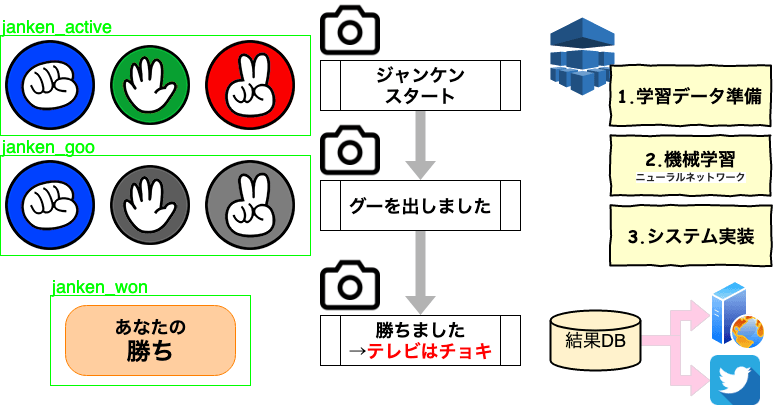
メールデータのマルチバイト文字処理
SendGridのInbound Email Parse向けPHP APIを公開しましたが、受信メールアドレスにより文字化けが発生しました。
SendGrid-Inbound Email Parse Webhookでメール受信をPUSH(第2回)
PHPでメールデータ取り扱い時には、サーバー側のphp.iniなどの文字コード設定など、よく悩まされます。
SendGridでは、POSTでcharsetsデータを送付してきますが、そのcharsetを用いてmb_convert_encoding関数を用いて、エンコーディング変換しても文字化けが発生しました。
文字コード変換の便利な関数を紹介しているサイトがありましたので、紹介しておきます。これらの関数を用いて、文字化けが解消するケースもありました。
基本的に、今回のSendGridnoInbound Email Parseは、IoT向けなので、必要な部分を絞ってメール情報を利用すれば運用回避もできるのですが、文字コードの正確なでコード処理が必要な場面もあり、以下関数を利用させて頂きました。
/**
* 日本語文字列の文字コード判定(ASCII/JIS/eucJP-win/SJIS-win/UTF-8 のみ)
*/
function detect_encoding_ja( $str )
{
$enc = @mb_detect_encoding( $str, 'ASCII,JIS,eucJP-win,SJIS-win,UTF-8' );
switch ( $enc ) {
case FALSE :
case 'ASCII' :
case 'JIS' :
case 'UTF-8' : break;
case 'eucJP-win' :
// ここで eucJP-win を検出した場合、eucJP-win として判定
if ( @mb_detect_encoding( $str, 'SJIS-win,UTF-8,eucJP-win' ) === 'eucJP-win' ) {
break;
}
$_hint = "\xbf\xfd" . $str; // "\xbf\xfd" : EUC-JP "雀"
// EUC-JP -> UTF-8 変換時にマッピングが変更される文字を削除( ≒ ≡ ∫ など)
mb_regex_encoding( 'EUC-JP' );
$_hint = mb_ereg_replace( "\xad(?:\xe2|\xf5|\xf6|\xf7|\xfa|\xfb|\xfc|\xf0|\xf1|\xf2)", '', $_hint );
$_tmp = mb_convert_encoding( $_hint, 'UTF-8', 'eucJP-win' );
$_tmp2 = mb_convert_encoding( $_tmp, 'eucJP-win', 'UTF-8' );
if ( $_tmp2 === $_hint ) {
// 例外処理( EUC-JP 以外と認識する範囲 )
if (
// SJIS と重なる範囲(2バイト|3バイト|iモード絵文字|1バイト文字)
! preg_match( '/^(?:'
. '[\x8E\xE0-\xE9][\x80-\xFC]|\xEA[\x80-\xA4]|'
. '\x8F[\xB0-\xEF][\xE0-\xEF][\x40-\x7F]|'
. '\xF8[\x9F-\xFC]|\xF9[\x40-\x49\x50-\x52\x55-\x57\x5B-\x5E\x72-\x7E\x80-\xB0\xB1-\xFC]|'
. '[\x00-\x7E]'
. ')+$/', $str ) &&
// UTF-8 と重なる範囲(全角英数字|漢字|1バイト文字)
! preg_match( '/^(?:'
. '\xEF\xBC[\xA1-\xBA]|[\x00-\x7E]|'
. '[\xE4-\xE9][\x8E-\x8F\xA1-\xBF][\x8F\xA0-\xEF]|'
. '[\x00-\x7E]'
. ')+$/', $str )
) {
// 条件式の範囲に入らなかった場合は、eucJP-win として検出
break;
}
// 例外処理2(一部の頻度の多そうな熟語は eucJP-win として判定)
// (珈琲|琥珀|瑪瑙|癇癪|碼碯|耄碌|膀胱|蒟蒻|薔薇|蜻蛉)
if ( mb_ereg( '^(?:'
. '\xE0\xDD\xE0\xEA|\xE0\xE8\xE0\xE1|\xE0\xF5\xE0\xEF|\xE1\xF2\xE1\xFB|'
. '\xE2\xFB\xE2\xF5|\xE6\xCE\xE2\xF1|\xE7\xAF\xE6\xF9|\xE8\xE7\xE8\xEA|'
. '\xE9\xAC\xE9\xAF|\xE9\xF1\xE9\xD9|[\x00-\x7E]'
. ')+$', $str )
) {
break;
}
}
default :
// ここで SJIS-win と判断された場合は、文字コードは SJIS-win として判定
$enc = @mb_detect_encoding( $str, 'UTF-8,SJIS-win' );
if ( $enc === 'SJIS-win' ) {
break;
}
// デフォルトとして SJIS-win を設定
$enc = 'SJIS-win';
$_hint = "\xe9\x9b\x80" . $str; // "\xe9\x9b\x80" : UTF-8 "雀"
// 変換時にマッピングが変更される文字を調整
mb_regex_encoding( 'UTF-8' );
$_hint = mb_ereg_replace( "\xe3\x80\x9c", "\xef\xbd\x9e", $_hint );
$_hint = mb_ereg_replace( "\xe2\x88\x92", "\xe3\x83\xbc", $_hint );
$_hint = mb_ereg_replace( "\xe2\x80\x96", "\xe2\x88\xa5", $_hint );
$_tmp = mb_convert_encoding( $_hint, 'SJIS-win', 'UTF-8' );
$_tmp2 = mb_convert_encoding( $_tmp, 'UTF-8', 'SJIS-win' );
if ( $_tmp2 === $_hint ) {
$enc = 'UTF-8';
}
// UTF-8 と SJIS 2文字が重なる範囲への対処(SJIS を優先)
if ( preg_match( '/^(?:[\xE4-\xE9][\x80-\xBF][\x80-\x9F][\x00-\x7F])+/', $str ) ) {
$enc = 'SJIS-win';
}
}
return $enc;
}
function decode_mimeheader($str) {
$enc_r = array( // 変換するエンコーディング文字列を設定
'iso-2022-jp' => 'iso-2022-jp-ms' ,
'shift_jis' => 'sjis-win' ,
'euc-jp' => 'eucjp-win' ,
'utf-8' => 'utf-8'
);
$str = str_replace('?==?' , "?=\n=?" , $str); // 未改行文字対策
$decode_str = '';
foreach (preg_split('/\s/', $str) as $split_str) { // SPACEで分割
if (strlen($split_str) === 0) {
$decode_str .= ($decode_str != '' ? ' ' : '');
continue;
}
if (preg_match('/(.*?)=\?([^\?]+)\?([^\?]+)\?([^\?]+)\?=(.*?)$/', $split_str, $matches)) { // =?[Charset]?[Text]?=形式の場合
$enc_str = strtolower($matches[2]);
$from_enc = isset($enc_r[$enc_str]) ? $enc_r[$enc_str] : $enc_str;
if ($from_enc != '') {
$match_decode = null;
switch (strtoupper($matches[3])) {
case 'B':
$match_decode = base64_decode($matches[4]);
break;
case 'Q':
$match_decode = quoted_printable_decode($matches[4]);
break;
}
if (!is_null($match_decode)) { // 変換に成功した場合のみ変換後テキストを追加し次の行へ
$decode_str .= ($decode_str != '' ? ' ' : '') . mb_convert_encoding( $matches[1].$match_decode.$matches[5], mb_internal_encoding(), $from_enc );
continue;
}
}
}
// 変換できなかった場合、又は =?[Charset]?[Text]?= 形式でなかった場合は、テキストのキャラクタセットを自動検出して変換する
$decode_str .= ($decode_str != '' ? ' ' : '') . mb_convert_encoding( $split_str , mb_internal_encoding() , detect_encoding_ja( $split_str ) );
}
return $decode_str;
}




 Choki(チョキ)
Choki(チョキ)  Pa(パー)
Pa(パー)