
初期検討時のシステム構想
機械学習どころか、プログラム言語Pythonも全く初めて、Raspberry PiやWEBカメラなどインフラ関係も知識なし。
WEBからの情報などで、こんな感じにしたいと思い描いたのが以下のシステム構想。
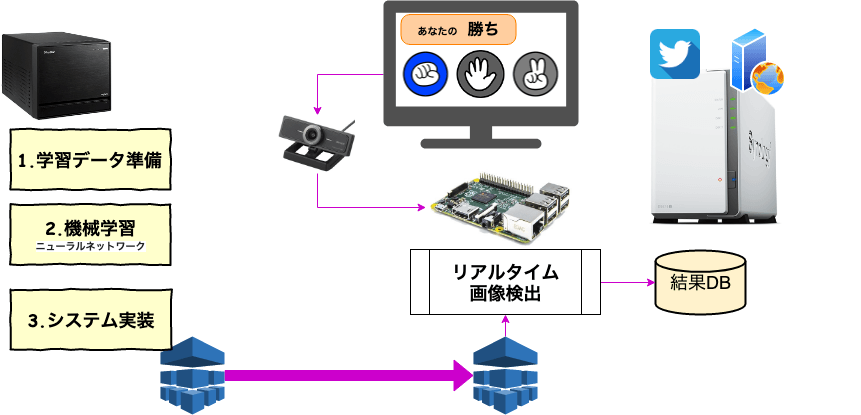
一般的なGeForce(GeForce GTX 960)ビデオカード搭載のWindowsメインマシン(Intel Core i7-6700 CPU)で機械学習・ニューラルネットワークを用いた学習モデルの作成。作成した学習モデルをRaspberry Pi 3
Model B+ へ移動し、Raspberry Piで画像検出を実施。
Raspberry Piでの画像検出結果により、じゃんけん結果をDBへ蓄積。蓄積したDBデータより、めざましじゃんけんの結果をホームページと速報としてTwitterで公開。
当初画像認識と画像検出の違いも分かっておらず、書籍などで紹介されていた画像認識を駆使したシステムを構築しようとしておりました。画像認識を試した時点ではRaspberry Piで処理可能に感じました。
画像認識・・・対象がアップ(画像一面)になっている画像の判定を行う
画像検出・・・対象が写り込んでいる画像より、対象を画像検出する
第一は、技術習得が1番のモチベーションであった、予期しないカメラのズレなどを考えても、画像検出のほうがシステムの安定稼働を望めるので、画像検出実装へ方針転換しました。実際には、画像認識は1日で実装出来たのですが、うまく動作せず、画像認識対象部分の画像切り取りなど、決め打ちの方式しか思いつかず、そうそうに画像検出に方針転換しました。他にも転用出来る素晴らしい技術に出会えたと思います。(Darknet、YOLO、Open CV、Python、DNN、ニューラルネットワーク)
V1での妥協と実装方式
本当は、リアルタイムでの画像検出を実装する予定でした。時間指定で動作するシステムよりもテレビさえ動いていれば、じゃんけんのスタートを自動検知し、結果を漏れなく収集するシステムを構想しました。
しかし、Raspberry Piの処理速度・信頼性より断念しました。画像検出中のRaspberry Piの発熱量など。
よって、V1ではめざましじゃんけん結果の判定の画像検出は、メインのWindowsマシンで実行しております。
めざましじゃんけんのみに特化して考えると、OpenCVの画像処理を駆使すれば軽くて高速なフィルタ作成も可能かなと考えています。
V1機能一覧と実装
| 機能名 | 実装 | |
| 画像検出フレームワーク準備 | 学習データ収集 | Raspberry PiとWEBカメラで、めざましじゃんけん実施時の画面キャプチャー取得 |
| 学習データ整理 | メインのWindowsマシンで実施。 LabelImgで学習したい内容のラベル登録 | |
| 学習 | メインのWindowsマシンでDarknetを用いて実施。 | |
| システム起動 | TV起動 | Raspberry PiよりNature Remo経由で実施。 |
| TVチャネル変更 | Raspberry PiよりテレビREGZAのWEB APIを用いて実施。 じゃんけん時の「青」「赤」「緑」ボタン操作もRaspberry PiよりWEB APIを用いて実施。 | |
| メインマシン起動 | メインマシン(Windows)の起動をRaspberry Piより実施 | |
| 画像検出 | 画像蓄積 | Raspberry PiのWEBカメラを用いて目覚ましテレビの画像をキャプチャー |
| 画像移動 | Raspberry PiでキャプチャーしたデータをWindowsのメインマインに移動 | |
| 画像検出 | Windowsマシンで画像検出を実施。 | |
| 検出結果 | 結果をDB登録 | Windowsマシンより画像検出結果をSynology NASのSQL DBへ登録 |
| 情報発信 | WEBコンテンツ | SQL DB情報よりWEBコンテンツの更新。Synologyで実施。 |
| Twitter発信 | WEBコンテンツ更新と同じタイミングでTwitter発信を実施。処理はSynologyで実施。 | |